FidoFetch Architecture
What’s FidoFetch
FidoFetch is a RSS/ATOM news reader service much like Google Reader. There are too many news articles and blog posts every second to read it all. In fact, most of it is not something you care about. FidoFetch watches which kinds of articles you like and only shows you things it thinks you will be interested in.
 Of course, Fido isn’t really a super smart canine, he’s software I wrote.
In fact, Fido isn’t really just one program, he’s a collection of many different programs doing different tasks.
Of course, Fido isn’t really a super smart canine, he’s software I wrote.
In fact, Fido isn’t really just one program, he’s a collection of many different programs doing different tasks.
In this article I’m going to take you through the backend architecture to FidoFetch. It’s been several iterations to arrive at this architecture, and I’m sure there will be many more.
Why?
 Some people may not like to share information about the inner workings of their projects.
I completely understand where they are coming from.
However, I’ve been primarily self taught in the area of scalable architectures.
What that really means is I’ve been reading about how other websites build and iterate on their architectures.
Their openness has allowed me to learn so much from their successes and failures.
I really do believe this has helped me succeed so well on my co-op work terms.
Some people may not like to share information about the inner workings of their projects.
I completely understand where they are coming from.
However, I’ve been primarily self taught in the area of scalable architectures.
What that really means is I’ve been reading about how other websites build and iterate on their architectures.
Their openness has allowed me to learn so much from their successes and failures.
I really do believe this has helped me succeed so well on my co-op work terms.
My hope is this article will help others learn from my mistakes and make their own really cool projects a reality. If you do find this article interesting or helpful, please let me know.
Goals
When building a system, I think it’s useful to make the goals clear. Ideally they should have quantitative measurements associated with them (as PDENG would profess) so you know when you’ve met them. But, I didn’t know what numbers I wanted to reach, I just wanted to get a working prototype out.
Here were my main goals with the architecture of the system:
1) Reading articles is most important
Being able to read and rate articles should be quick and responsive. The user interface should not lag despite a large load on the server. Having the most up to date articles is not as important.
2) Elastic Server Capacity
 I’m a student and while my co-op jobs have been quite good in terms of compensation, I don’t want to waste money on servers I don’t need.
Right now this is just a personal project, not a business.
So I only want to run the bare minimum of servers to run FidoFetch.
I’m a student and while my co-op jobs have been quite good in terms of compensation, I don’t want to waste money on servers I don’t need.
Right now this is just a personal project, not a business.
So I only want to run the bare minimum of servers to run FidoFetch.
One easy way to do this is to figure out how much capacity I need and run the correct number of servers. But what happens if HackerNews, Digg or reddit finds out about FidoFetch? It’s a fairly computationally intensive application and having many more users all of a sudden could be traumatic to the server.
Another solution is to have the system scale based on it’s current usage. If the system detects a high load, it boots up another instance in a cloud. Getting more capacity through EC2 or Rackspace isn’t hard at all to automate, the challenge is getting the software to make use of the additional capacity.
3) Ability to try different recommendation algorithms
FidoFetch is part of a learning project for me. I don’t know what the best algorithm is for recommending articles in a news feed. But that’s part of the fun, it’s an experiment.
So, I need to be able to try many different algorithms side by side. This would dictate that the architecture not be specific to any specific type of algorithm. This is also a problem I dealt with at Tagged during my internship.
4) Let others design the reader
I’m not a great visual designer. If you look at some of my projects it will become quite apparent. Some of them look the same in Links as they do in a graphical web browser…
So clearly I shouldn’t be the designer for the reader. Many people can make much more beautiful interfaces that would benefit from my platform. To that end, FidoFetch must be able to be used under someone else’s reader app (be it JavaScript, HTML5, BlackBerry, iOS, offline/desktop, Android, etc…).
Solution
Queues
 Goal #1 would require the ability to prioritize different parts of the system and hold unimportant computation for later.
This speaks to me as a great place to use a queue.
A queue would allow feed fetching and recommendation to happen behind the scenes when the server isn’t busy.
Goal #1 would require the ability to prioritize different parts of the system and hold unimportant computation for later.
This speaks to me as a great place to use a queue.
A queue would allow feed fetching and recommendation to happen behind the scenes when the server isn’t busy.
Goal #2 asks for the ability to scale server capacity and make use of the added capacity. A queue could allow for many different machines to do distinct units of computation and then store the results. There could be a set of queues for different job types (fetching a feed, recommending an article etc.) and each message in the queue could be a specific job. A set of workers could consume the message/job, do the task and then report the results.
For FidoFetch, I have at least one worker running for each type of job (and thus queue). When more server capacity is created, I just have my system start workers on the new machines that connect to the queuing server. The need for more servers can be detected by analyzing the queue. Two common metrics are the number of items in the queue and the time it takes from entering the queue until the job is processed. Testing the number of items in the queue is really straight forward to implement and is what I use.
Jobs
I designed the jobs in a specific way in order to achieve the scalability I wanted. The key things are:
- All messages representing jobs are JSON dictionaries representing the parameters for the job.
- A job may be processed more than once by the same or different worker at different times or simultaneously
- A job represents a small section of work that will take no more than 4 minutes.
- If a job exceeds its run time, it will be placed back into the queue and processed by another worker with a back-off time
- If a job needs to be rerun more than 10 times, it is removed from queue and placed in a collection of buried items
- Each job can put multiple jobs into other queues for further processing
JSON Messages: I chose to standardize on JSON for the message format because I use it everywhere else in my application and it has libraries in so many languages.
Duplicate Processing: To make the queue more efficient and not waste time, I require only that messages are delivered. I don’t need a guarantee that jobs will only be processed once. This greatly complicates that architecture. It’s easier for to just write the software to handle duplicate runs by default. There’s not really any harm if a feed is fetched twice. In the case of recommending an article to a user, I have it set up in the database so that there are no duplicates on the article_key.
Time Limits: The time limit makes it easy for the queuing server to detect when there is an issue with a worker processing a job. If a job exceeds this time, the queue knows it’s ok to just put it in the queue again.
Back-off Time: This one came from experience. It turned out that if a job failed for some reason or another and was placed back into the queue and run again immediately, it was likely to fail again. Often there was some resource that wasn’t working or being slow (a database or a third party feed). When the job was placed back into the queue, it would just fail again.
Had the job been held back for a few seconds there would not have been an issue. I had the queue wait a bit before reinserting the job into the queue. I had the wait time double each time the job failed. Ethernet does something similar when there is a packet collision. Except Ethernet uses a random back-off time otherwise the two machines that detected the packet collision would just keep sending on the same intervals.
Retry Limit: This one was also learned the hard way. For a while I had the database misconfigured and it would get very slow after a while (24 hours+). Eventually it would stop serving requests and the worker would detect the failure immediately and tell the queue it failed. The worker would get another job right away and try again. The job would fail and then be in back-off mode.
Once the timeout was complete all the jobs would come back again and hammer the database server even further. This made it very difficult to go into the server and restart the database. So I implemented a limit of retries. When the limit is reached, the jobs go into a special buried queue. Once I fixed the problem (in this case restarting the database), I could just kick the jobs back into the regular queue.
Chain of Jobs: Now this part has been really helpful in keeping FidoFetch running. I’m going to need a separate section to explain this. For now it suffices to say that each worker has the ability to insert subsequent tasks in other queues for processing.
Chain of Jobs
Chaining of jobs is a very important part of FidoFetch’s architecture. It’s a create model for writing distributed processing software in. It’s neither a new concept nor a complex one, but it is very cool (in my opinion).
In FidoFetch, the process to fetch a feed and then send it to a user’s to read list is broken into several parts. Six to be exact. Each part deals with a specific task that is separable from the others. It does not depend on what the other workers are currently doing. Essentially, the output of each job is the input of the next.
Do_Job3( Do_Job2( Do_Job1(user_key) ) )
The current job places the result of the job as a new job on the queue for the next job type. This can be thought of as a chain
user_key -> Worker1 -> Worker2 -> Worker3
Now, some jobs will actually have multiple return values that will create multiple jobs on the next queue. For example, returning a list of all the user’s who need to be notified about a new article will return multiple users. The actual notification of a user requires only the user_key of that user and is independent of the other users that need to be notified. Thus multiple jobs are placed into the queue, one for each user_key.
By separating the overall task in multiple parts, we gain a few things:
- Failure of one part does not require loosing the work so far
- Ability to distribute a seemingly single task into multiple pieces
- Ability to write different workers in different languages (maybe C++ for something that needs to be high performing)
- Ability to add more workers for a specific task that either happens more often or takes longer.
It’s extremely useful. Right now everything is written in Python but I do soon plan on writing some workers in C++ in the future. The ability to add workers for a specific task has also been especially useful. The feed fetching operation requires very little CPU but just time for the remote server to respond. If I had just one worker doing feed fetching, it would stall the whole process if one server was particularly slow. I run several feed fetching workers at the same time so faster feeds get processed quickly.
FidoFetch’s Chain
Now I’m going to delve into how I decided to split up the tasks. These are not all the job types that are in FidoFetch. There are some other tasks that get run in the background, but they are not in the main chain. I’ll cover those tasks later.
Here’s FidoFetch’s job chain:
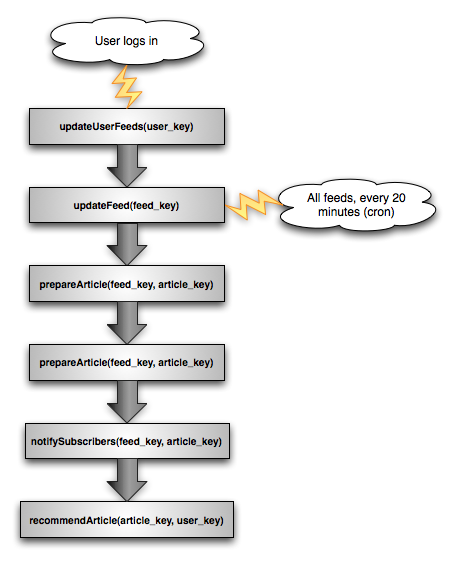
Entrance Points
There are two ways to kick off the process. The first way is on login. When a user logs into FidoFetch, the system adds a job to update their feeds with the updateUserFeeds task type. There is probably already stuff for the user to read, but lets ensure they have lots of interesting stuff to read by rechecking all of their feeds.
The second way is through a cron job. Wait a minute… weren’t we designing a distributed system? Cron seems very non-distributed doesn’t it…
Well, yes. This is true. But I have reasons: 1) I want it to start automatically and 2) queuing the same job does not violate the principles we set in Jobs section above. So if I have all the servers just queuing jobs, the system should be prepared for this. The system is, which we’ll talk about later in the updateFeed worker section.
So back to the entrance point. Every 20 minutes (totally customizable), the system queues a job for each feed that there are subscribers (a list I maintain, lookups are in constant time). This happens with a python script. The twenty minutes is just a reasonable number I picked.
updateUserFeeds(user_key)
The updateUserFeeds task’s name is somewhat of a misnomer. Technically it doesn’t update the feeds of that user. We didn’t design this who chaining system for nothing!
What actually happens in this job is quite simple. The worker is passed (as a part of the message) the user_key of a user. The key is an arbitrary string (I choose to use a hash of the username, but the worker doesn’t care). The worker then looks up in the database all of the feeds that the user is currently subscribed to (in constant time).
Then the worker takes a look at all the feeds (each is a constant time lookup in the database) and reduces the list to those that haven’t been updated in over 15 minutes. The 15 minutes is again arbitrary, but is a reasonable number for current operation. Then, for each feed remaining, the worker places a job in the queue for updateFeed().
updateFeed(feed_key)
This worker does what it’s name implies. It updates the feed given to it. First it looks up in the database to see if the feed has been checked in the past 15 minutes. If it has, then the worker is done with the task.
The reason the worker looks up the feed’s last update time in the database again is to be consistent with our rules for jobs. Earlier we said that a task it not guaranteed to only be run once. This means that two different workers (maybe to different machines) may receive the job. To ensure that we don’t hit the remote server too often (and waste our time), we only check if the feed data is at least 15 minutes old.
If the feed hasn’t been updated recently, the worker fetches and parses the feed. In past implementations of FidoFetch I wrote my own RSS/ATOM processor. I think it’s something many naive developers have done. Don’t bother. While RSS and ATOM are standards, there implementations are far from standardized across the web. There are so many different styles of generating feeds and so many malformed feeds. It’s not worth trying to figure out all the nuances of feed parsing.
This time I was smart, or rather a co-worker (a really awesome intern from a university in New Mexico) was for me. He pointed me in the direction of the Universal Feed Parser. It’s a feed parser in python that does an awesome job. It’s really quite an awesome piece of software. The interface is also quite intuitive and pythonic.
So the worker grabs the feed and checks if each article exists in the database already. The key for the articles is a hash of some of the meta information of the article. Often the guid or url of the article is used. This makes lookups very fast.
Now, for each article that was new, the worker saves the article data and queues a job in the prepareArticle(feed_key, article_key) queue.
prepareArticle(feed_key, article_key)
This workers is the first to do something a little more interesting than the previous ones. This worker is given an article for a given feed to work on.
It grabs the article from the database and the processes it. Internally it actually runs through a list of processors (which are just python modules I wrote). This is part of one of the requirements we discussed earlier, the ability to try multiple learning algorithms at the same time.
Different algorithms require different pre-processing of articles. A common one is tokenizing and generating n-grams. This processing is independent of the user the article is being recommended to and is static. That means that pre-processing an article is a perfect sub task to be done ahead of time.
Once the preparation is complete, it just enqueues another job into the notifySubscribers(feed_key, article_key) queue.
notifySubscribers(feed_key, article_key)
This worker is pretty simple. It looks up all the users who are subscribed to a given key. I have such a list stored under the feed_key in the database so this is a constant time operation.
Then, for each person in the list, the article is added to the recommendArticle(article_key, user_key) queue.
recommendArticle(article_key, user_key)
This worker is the main point in the application. This is what makes FidoFetch smart. This is where Fido decides if an article is something you’d be interested in.
This worker runs through each recommendation algorithm (each is a python module) and calculates the recommendation. It stores the recommendation in a articlesToRead list keyed by the user_key.
If this worker is run more than once, the worker catches this by seeing it’s already rated this article for this user.
This worker does not report to anything else. The chain is done!
Other Tasks
Not everything fits into the chain. There are a few tasks that need to be completed but don’t depend on other tasks. In other systems this may include cleaning up temporary files, updating server code etc.
regenerateModels(user_key)
For many algorithms, there can be a huge performance boost in pre-generating some sort of model every once in a while. Not all algorithms can do this but a lot can. So each algorithm has the option to add itself to the list of things that should be run periodically.
These tasks tend to be really heavy. Regenerating just one of the models for my interests takes about 3 minutes if there is no other load. Putting this task in a distributed worker queue makes a lot of sense.
markArticleRead(article_key, user_key)
Once you read an article, there are a lot of things that change than just your articlesToRead list. There are other indexes that can quickly show what everyone else thought of a given article, what people think of certain feeds in general and so on.
Previously, all these indexes were updated as soon as you click read. But that left the interface feeling slow. Since reading articles is the primary use for FidoFetch, a snappy interface is important. Running these less important index updates asynchronously works great.
Queuing System
So we’ve discussed at length how FidoFetch uses queues, but what does FidoFetch use for it’s queuing service?
I evaluated several options for FidoFetch. Amazon’s Simple Queuing Service, SpringSource’s RabbitMQ, ZeroMQ, Apache’s ActiveMQ and even using a database as the queue.
Once again one of my coworkers suggested a product he has used in the past, beanstalkd.
Beanstalkd
Beanstalkd is a simple and straightforward worker queue. Now technically it is not a distributed worker queue. However, workers can connect to it from anywhere and start processing jobs.
My design requirements do not require the absence of any single point of failure. If this were to be the case, I would have to use one of the other queuing services. FidoFetch was designed to be scalable for my needs.
There are clients for Beanstalkd in many languages and it has the basic features I need. I use beanstalkc for python.
I also wrote a simple monitoring script for ganglia.
The Database
FidoFetch needs somewhere to store all the articles, subscriptions, rating data etc. The design of the system requires multiple servers be able to access the information in a scalable fashion.
Since the server farm needs to be elastic, the database needs to be able to grow and shrink in terms of nodes.
Riak
Riak is the database that powers FidoFetch, there were a few reasons I choose this database:
- Free (I’m a student…)
- Distributed
- Fast lookups on key
- Elastic (Nodes can leave an join the network without manual rebalancing)
- Fault tolerant (Nodes can die and come back, downloading only the changed data)
- Map/Reduce tools
- Intuitive API
Riak is really quite awesome. It’s written in Erlang and is really straightforward to use. I do admit I had some trouble with the Map/Reduce functionality but I’ve managed to find workarounds.
I recommend you check out the riak wiki for more information.
Conclusion
I’ve covered what I wanted to discuss about FidoFetch’s architecture. I hope you found it interesting despite the length. I hope that you will also find it useful or that it at least gets your brain churning.
So far FidoFetch’s architecture has been performing great. I expect there will be further iterations.
Thanks for reading, please shoot me an email with any thoughts.